
Im trying to load data from a redshift cluster but the import fails because the dataset is too large to be imported using SPICE. (Figure 1) How can I import…for example…300k rows every hour so that I can slowly build up the dataset to the full dataset? Maybe doing an incremental refresh is the solution? The problem is I don’t understand what the “Window size” configuration means. Do i put 300000 in this field (Figure 2)?
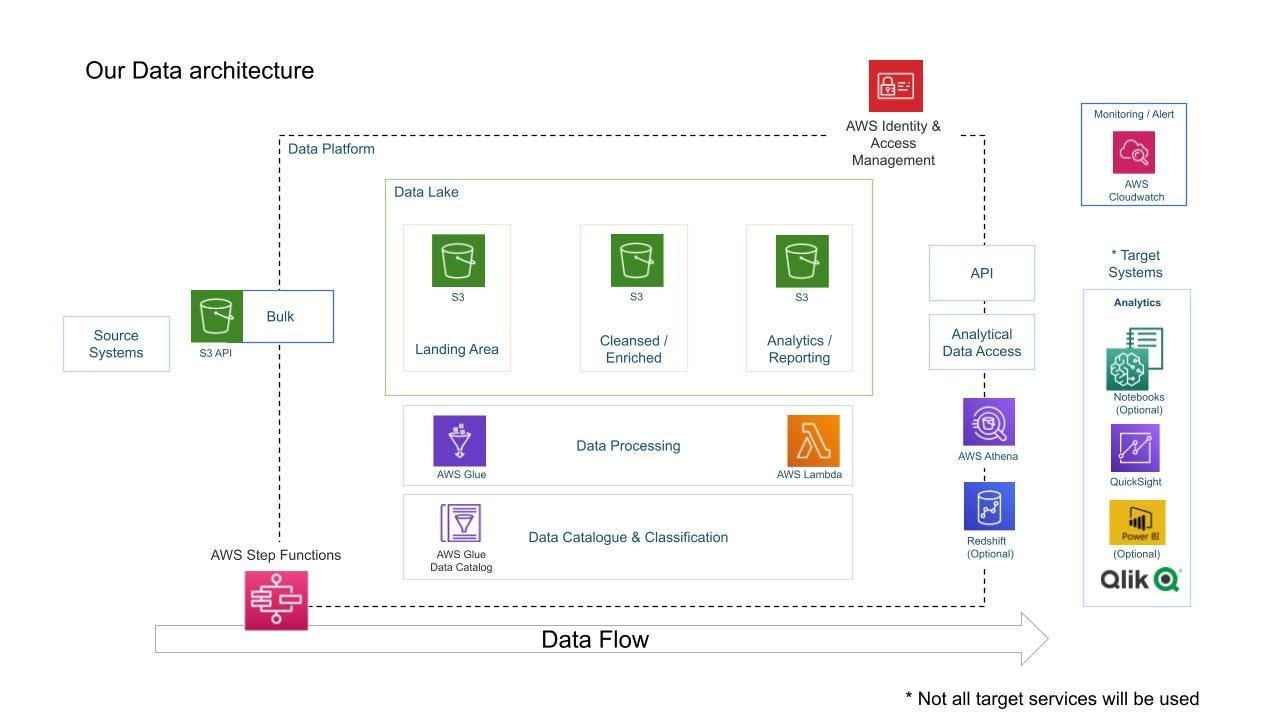
Data Engineering Project using AWS Lambda, Glue, Athena and QuickSight, by Ishaan Rawat
Cloud Computing Glossary of Terms
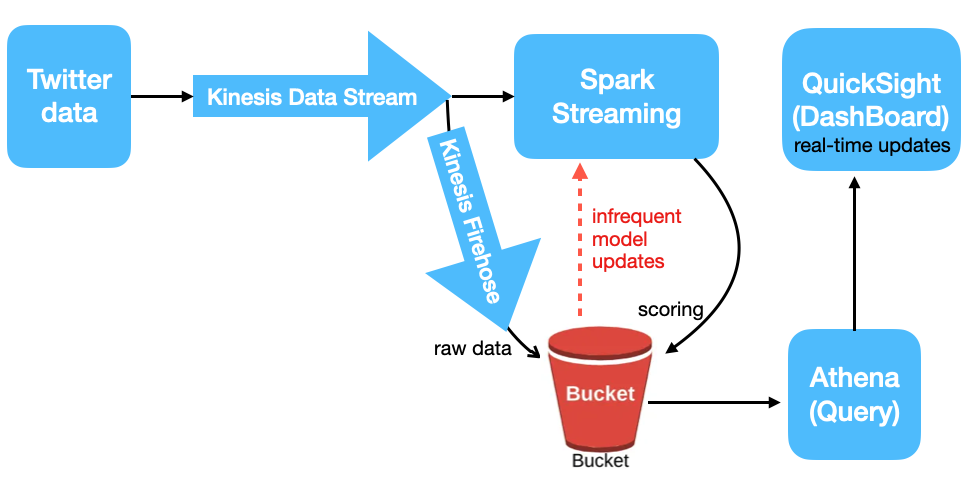
How to Build a Real-Time Twitter Analysis Application Using Big Data Tools, by Chuangxin Lin

Data Science Courses in Python, R, SQL, and more
Dataset too large to import. How can I import certain amount of rows every x hours? - Question & Answer - QuickSight Community
AWS Archives - Solita Data

Quicksight: Deep Dive –

Quicksight: Deep Dive –
.jpg&optimizer=image)
Getting Started with nannyML
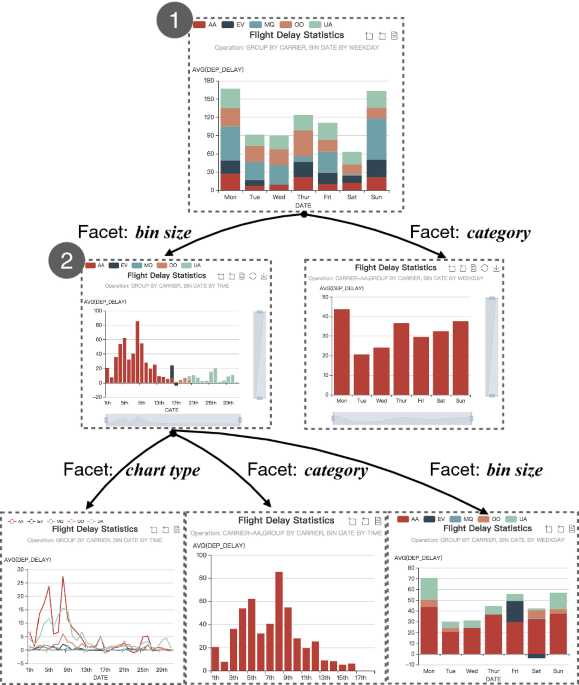
Making data visualization more efficient and effective: a survey







