
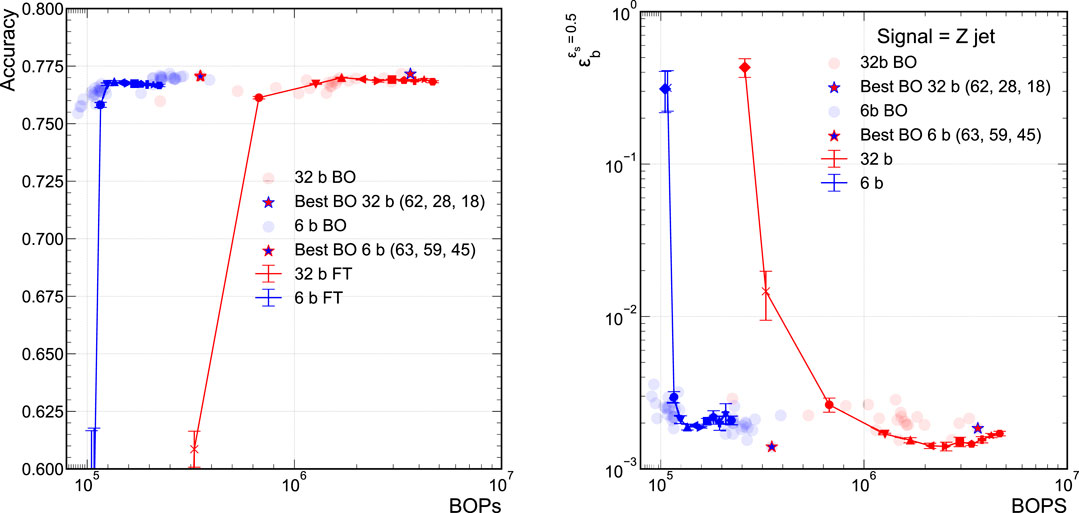
Frontiers Ps and Qs: Quantization-Aware Pruning for Efficient Low Latency Neural Network Inference

PDF] Channel-wise Hessian Aware trace-Weighted Quantization of Neural Networks

Pruning and quantization for deep neural network acceleration: A survey - ScienceDirect

A2Q+: Improving Accumulator-Aware Weight Quantization
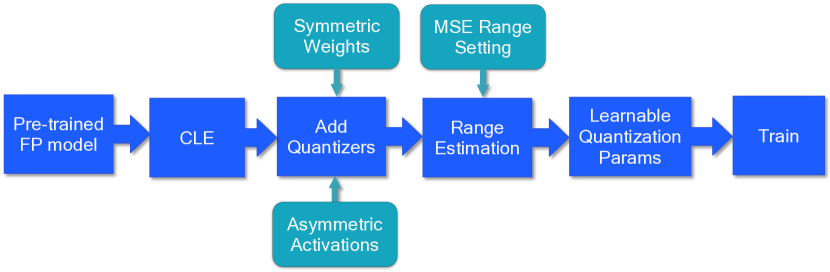
2106.08295] A White Paper on Neural Network Quantization
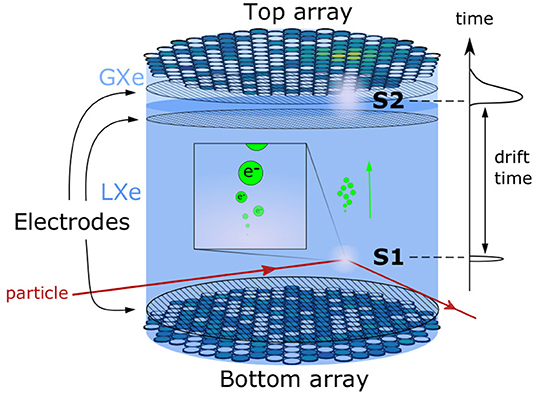
Frontiers Domain-Informed Neural Networks for Interaction Localization Within Astroparticle Experiments

Pruning and quantization for deep neural network acceleration: A survey - ScienceDirect

PDF) End-to-end codesign of Hessian-aware quantized neural networks for FPGAs and ASICs

2006.10159] Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors

Machine Learning Systems - 10 Model Optimizations







