miro.medium.com/v2/resize:fit:1400/1*tIkCREGvFWTIK
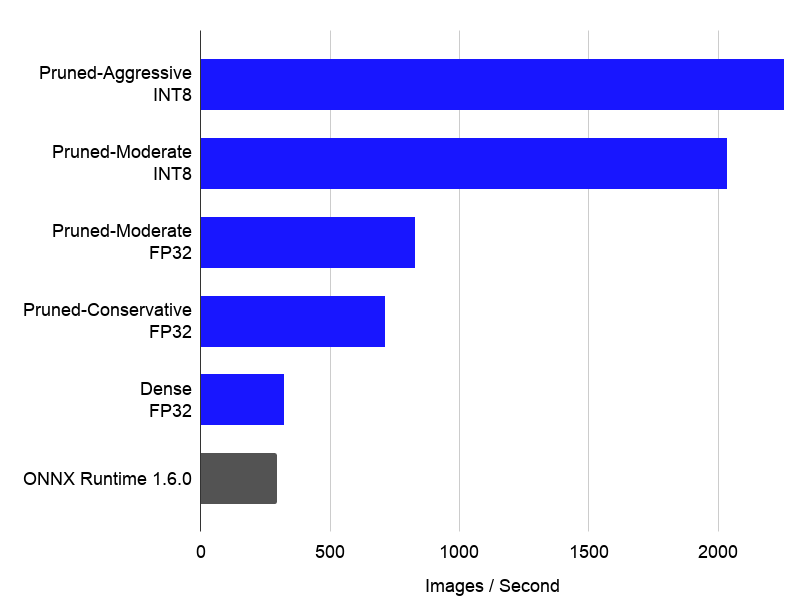
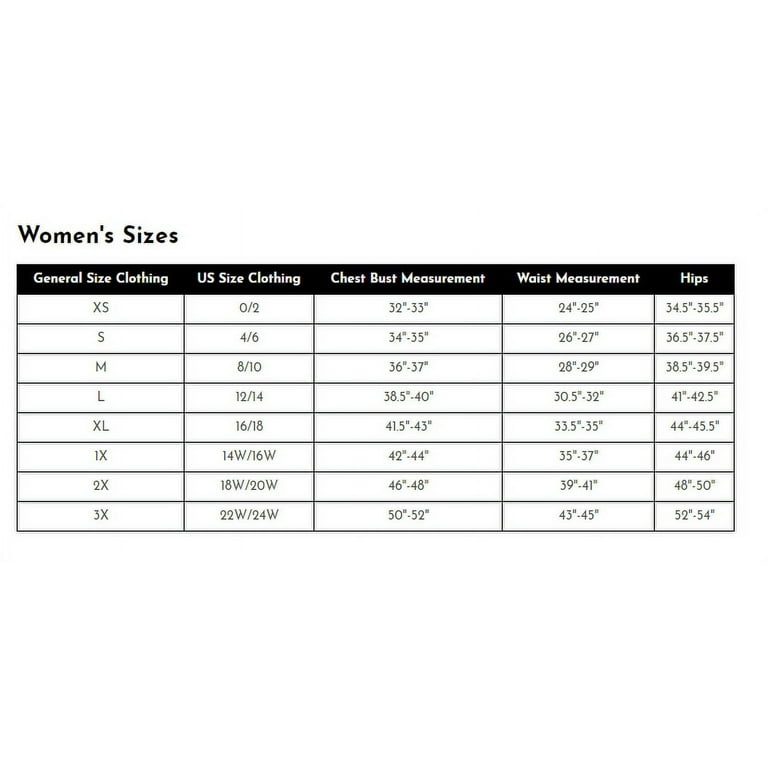
ResNet-50 on CPUs: Sparsifying for Better Performance

Poor Man's BERT - Exploring layer pruning

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

Running Fast Transformers on CPUs: Intel Approach Achieves Significant Speed Ups and SOTA Performance
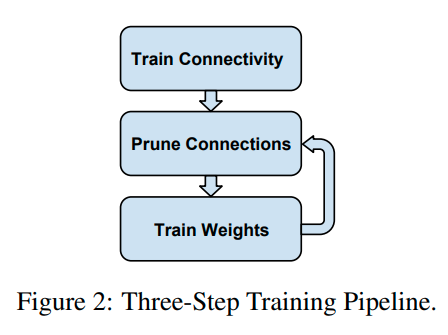
Neural Network Pruning Explained

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

BERT-Large: Prune Once for DistilBERT Inference Performance - Neural Magic

How to Compress Your BERT NLP Models For Very Efficient Inference
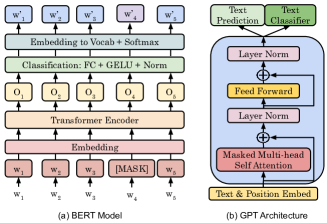
2307.07982] A Survey of Techniques for Optimizing Transformer Inference
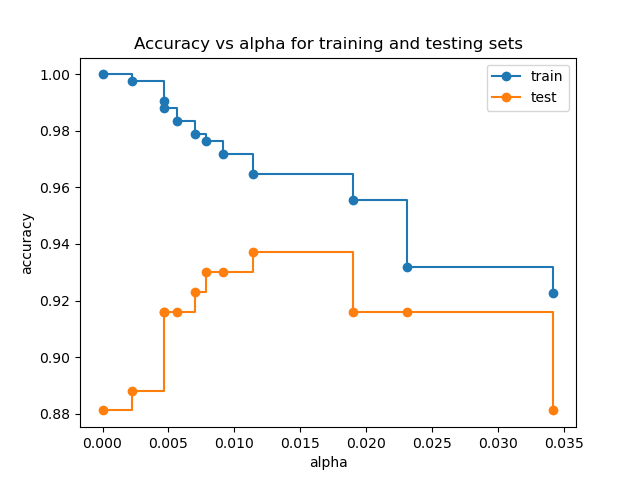
Neural Network Pruning Explained

PDF) The Optimal BERT Surgeon: Scalable and Accurate Second-Order Pruning for Large Language Models

PDF) Prune Once for All: Sparse Pre-Trained Language Models