
Share
Reinforcement Learning should be better seen as a “fine-tuning” paradigm that can add capabilities to general-purpose foundation models, rather than a paradigm that can bootstrap intelligence from scratch.

Do You Really Need Reinforcement Learning (RL) in RLHF? A New
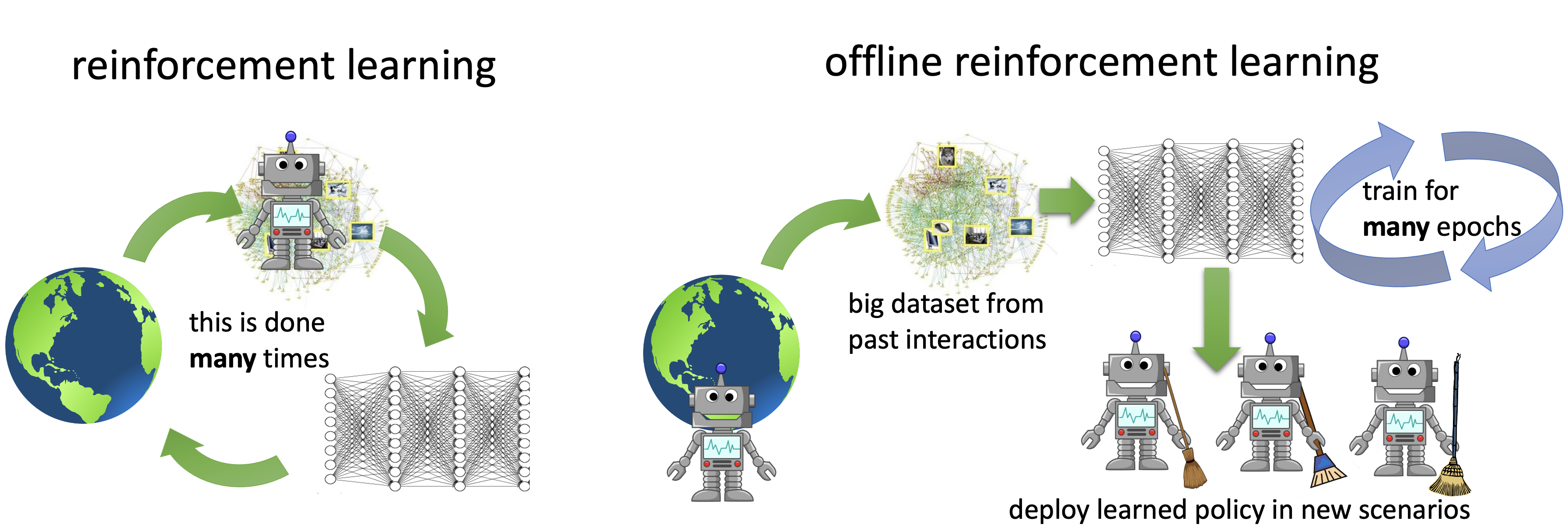
Offline Reinforcement Learning: How Conservative Algorithms Can
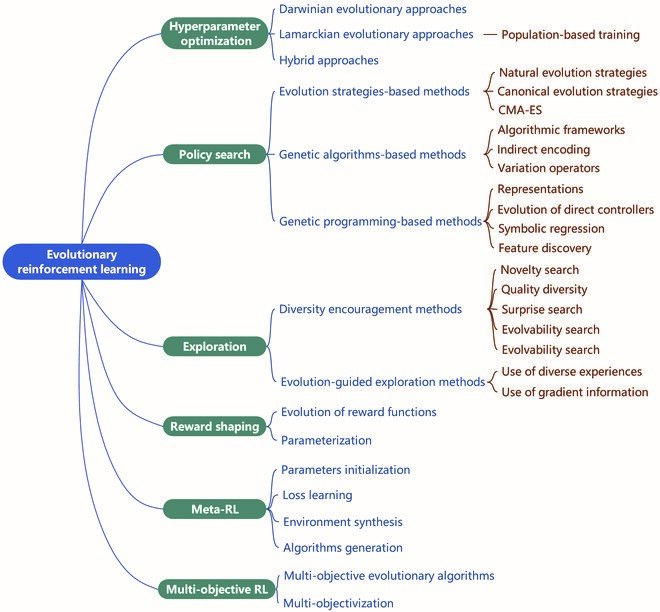
Evolutionary reinforcement learning promises further advances in

Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU

images./is/image/synopsys/reinforcemen

Electronics, Free Full-Text
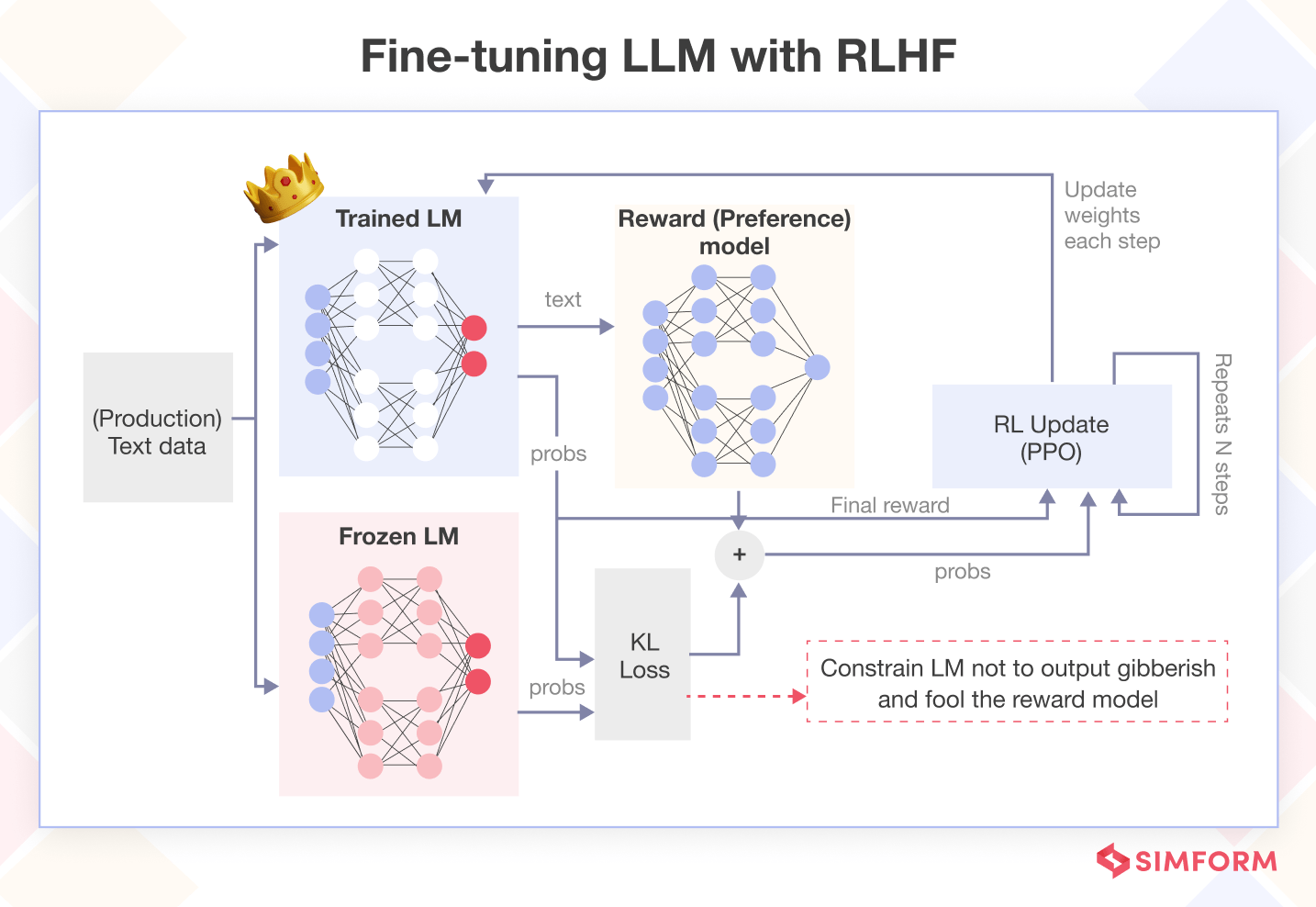
What is Reinforcement Learning from Human Feedback (RLHF)?
What is Reinforcement Learning? – Overview of How it Works
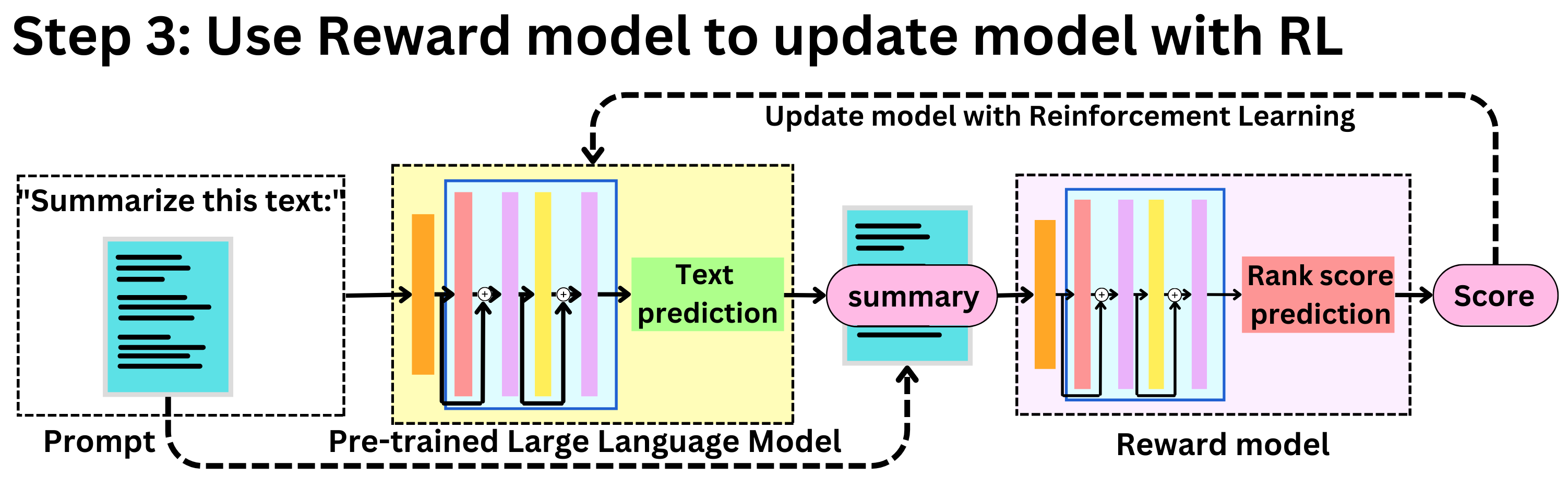
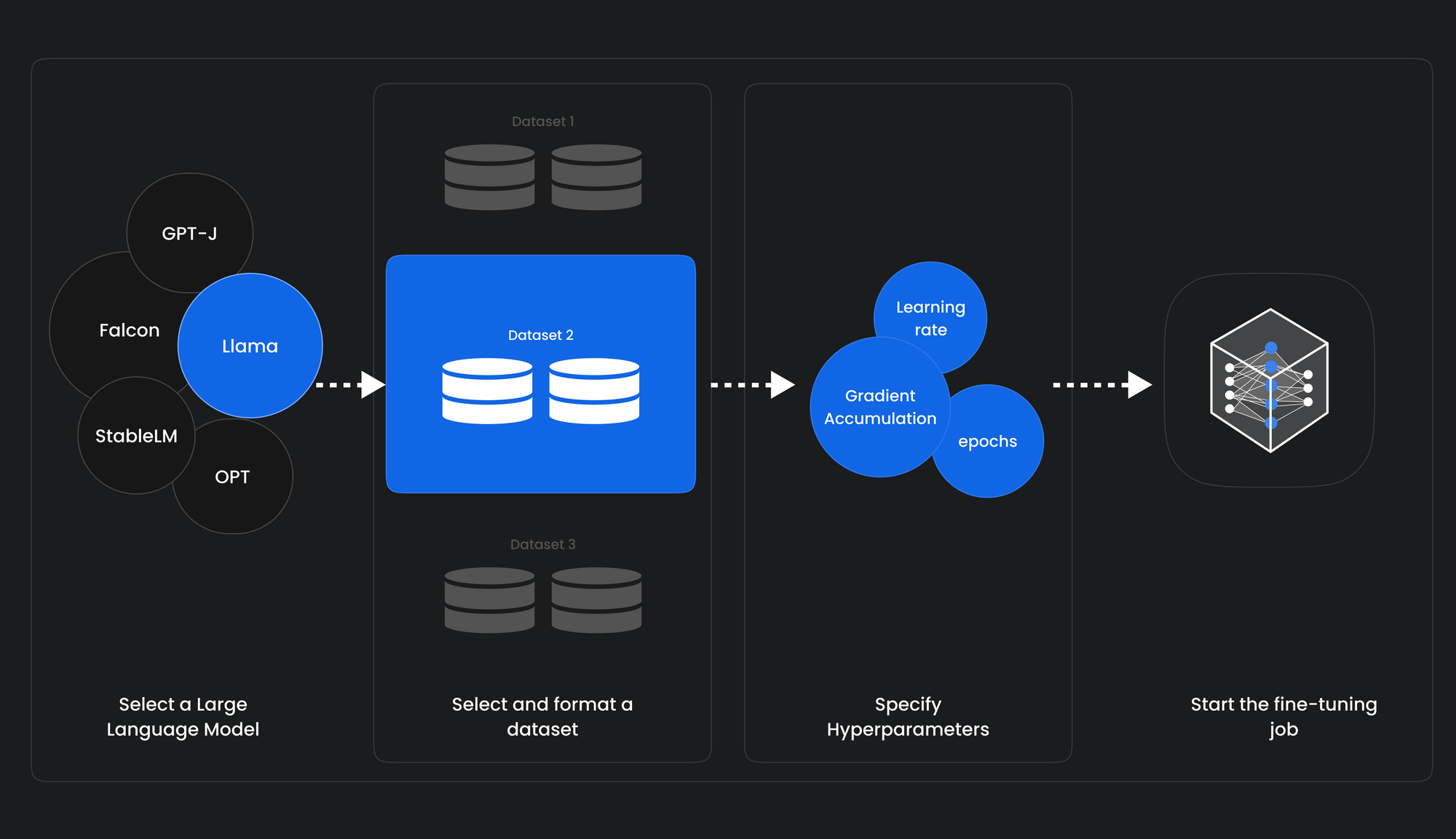
The AiEdge+: How to fine-tune Large Language Models with Intermediary models
Related products


You may also like


